Artificial intelligence has long been a useful tool for helping scientists carry out and analyze experiments in their pursuit for knowledge. But are we soon approaching an era where AI can test its own hypotheses, take the results, and use them to design new hypotheses to test: no scientists required. In fact, that era of machines-as-scientists may already be here.
In this excerpt from The Science of Science, Dashun Wang, a data researcher and associate professor of management and organizations at the Kellogg School, and his coauthor Albert-László Barabási explain.
Can Science Be Accelerated?
In the mid eighteenth century, the steam engine jump started the Industrial Revolution, affecting most aspects of daily life and providing countries that benefitted from it with a new pathway to power and prosperity. The steam engine emerged from the somewhat counterintuitive yet profound idea that energy in one form—heat—can be converted to another—motion. While some see the steam engine as one of the most revolutionary ideas in science, it was arguably also the most overlooked [1]. Indeed, ever since we knew how to use fire to boil water, we’ve been quite familiar with that annoying sound the kettle lid makes as it vibrates when water reaches a rolling boil. Heat was routinely converted to motion in front of the millions, but for centuries no one seemed to recognize its practical implications.
The possibility that breakthrough ideas like the steam engine hover just under our noses, points to one of the most fruitful futures for the science of science. If our knowledge about knowledge grows in breadth and quality, will it enable researchers and decision makers to reshape our discipline, “identify areas in need of reexamination, reweight former certainties, and point out new paths that cut across our assumptions, heuristics, and disciplinary boundaries”[2]?
Machines have aided the scientific process for decades. Will they be able to take the next step, and help us automatically identify promising new discoveries and technologies? If so, it could drastically accelerate the advancement of science. Indeed, scientists have been relying on robot-driven laboratory instruments to screen for drugs and to sequence genomes. But, humans are still responsible for forming hypotheses, designing experiments, and drawing conclusions. What if a machine could be responsible for the entire scientific process—formulating a hypothesis, designing and running the experiment, analyzing data, and deciding which experiment to run next—all without human intervention? The idea may sound like a plot from a futuristic sci-fi novel, but that sci-fi scenario has, in fact, already happened. Indeed, a decade ago, back in 2009, a robotic system made a new scientific discovery with virtually no human intellectual input [3].
Close the Loop
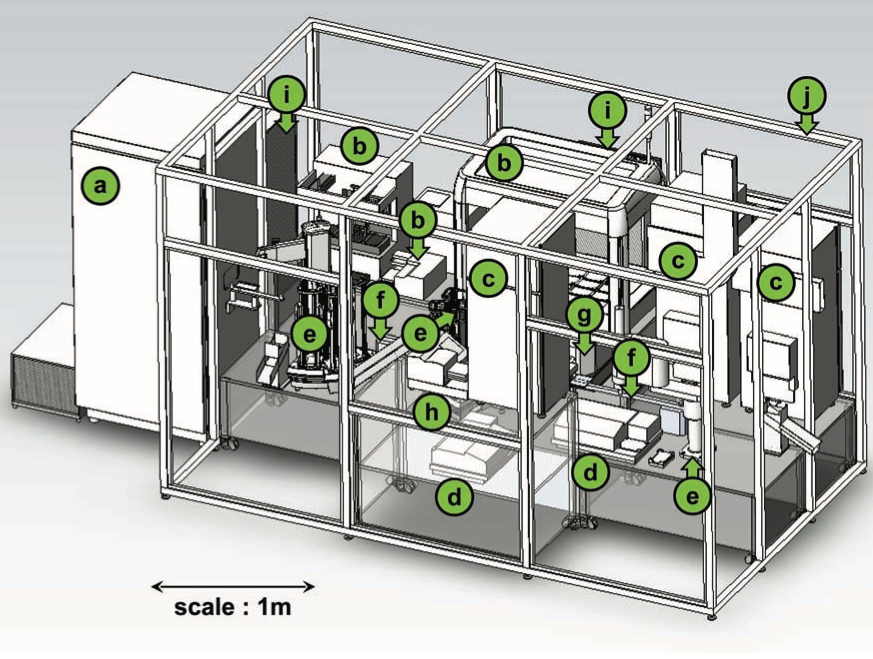
The figure below shows “Adam,” our trusty robot scientist, whose training ground was baker’s yeast, an organism frequently used to model more complex life systems. While yeast is one of the best studied organisms, the function of ten to 15 percent of its roughly 6,000 genes remains unknown. Adam’s mission was to shed light on the role of some of these mystery genes. Adam was armed with a model of yeast metabolism and a database of the genes and proteins necessary for metabolism in other species. Then it was set loose, with the role of the supervising scientists being limited to periodically add laboratory consumables and to remove waste.
Adam sought out gaps in the metabolism model, aiming to uncover “orphan” enzymes, which haven’t been linked to any parent genes. After selecting a desirable orphan, Adam scoured the database for similar enzymes in other organisms, along with their corresponding genes. Using this information, Adam then hypothesized that similar genes in the yeast genome may encode the orphan enzyme and began to test this hypothesis.
It did so by performing basic operations: It selected specified yeast strains from a library held in a freezer, inoculated these strains into microtiter plate wells containing rich medium, measured their growth curves, harvested cells from each well, inoculated these cells into wells containing defined media, and measured the growth curves on the specified media. These operations are very similar to the tasks performed by a lab assistant, but they are executed robotically.
Adam is a good lab assistant, but what truly makes this machine so extraordinary is its ability to “close the loop,” acting as a scientist would. After analyzing the data and running follow-up experiments, it then designed and initiated over a thousand new experiments. When all was said and done, Adam formulated and tested 20 hypotheses relating to genes that encode 13 different orphan enzymes. The weight of the experimental evidence for these hypotheses varied, but Adam’s experiments confirmed 12 novel hypotheses.
To test Adam’s findings, researchers examined the scientific literature on the 20 genes investigated. They found strong empirical evidence supporting six of Adam’s 12 hypotheses. In other words, six of Adam’s 12 findings were already reported in the literature, so technically they were not new. But they were new to Adam, because it had an incomplete bioinformatics database, hence was unaware that the literature has already confirmed these six hypotheses. In other words, Adam arrived at these six findings independently.
Most importantly, Adam discovered three genes which together coded for an orphan enzyme. This finding represents new knowledge that did not yet exist in the literature. And when researchers conducted the experiment by hand, they confirmed Adam’s findings. The implication of this is stunning: A machine, acting alone, created new scientific knowledge.
We can raise some fair criticisms about Adam, particularly regarding the novelty of its findings. Although the scientific knowledge “discovered” by Adam wasn’t trivial, it was implicit in the formulation of the problem, so its novelty is, arguably, modest at best. But the true value of Adam is not about what it can do today, but what it may be able to achieve tomorrow.
As a “scientist,” Adam has several distinctive advantages. First, it doesn’t sleep. As long as it is plugged into a power outlet, it will unceasingly, doggedly putter away in its pursuit of new knowledge. Second, this kind of “scientist” scales, easily replicable into many different copies. Third, the engine that powers Adam—including both its software and hardware—is doubling in efficiency every year. The human brain is not.
Which means Adam is only the beginning. Computers already play a key role in helping scientists store, manipulate, and analyze data. New capabilities like those offered by Adam, however, are rapidly extending the reach of computers from analysis to the formulation of hypotheses [4]. As computational tools become more powerful, they will play an increasingly important role in the genesis of scientific knowledge. They will enable automated, high-volume hypothesis generation to guide high-throughput experimentation. These experiments will likely advance a wide range of domains, from biomedicine to chemistry to physics, and even to the social sciences [4]. Indeed, as computational tools efficiently synthesize new concepts and relation- ships from the existing pool of knowledge, they will be able to usefully expand that pool by generating new hypotheses and drawing new conclusions [4].
These advances raise an important next question: How do we generate the most fruitful hypotheses in order to more efficiently advance science?
The Next Experiment
To improve our ability to discover new, fruitful hypotheses, we need to develop a deeper understanding of how scientists explore the knowledge frontier, and what types of exploration—or exploitation—tend to be the most fruitful. Indeed, merely increasing the pool of concepts and relationships between them typically leads to a large number of low-quality hypotheses. Instead, we need to be discerning. One example of how to home in on valuable discoveries is the Swanson hypothesis [5]. Swanson posits that if concepts A and B are studied in one literature, and B and C in another, then the link between A and C may be worth exploring. Using this approach, Swanson hypothesized that fish oil could lessen the symptoms of Raynaud’s blood disorder and that magnesium deficits are linked to migraine headaches, both of which were later validated [5].
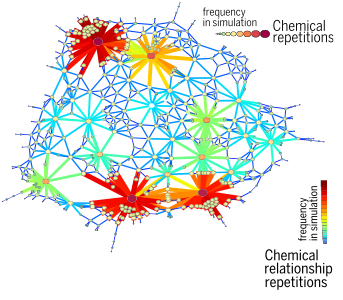
Recent attempts at applying computational tools to massive corpora of scientific texts and databases of experimental results have substantially improved our ability to trace the dynamic frontier of knowledge [8, 6]. Analyzing the abstracts of millions of biomedical papers published from 1983 to 2008, researchers identified chemicals jointly studied in a paper, represented specific research problems as links between various scientific entities, and organized them in a knowledge graph [6]. This graph allowed them to infer the typical strategy used by scientists to explore a novel chemical relationship.
For example, the figure above shows that scientists have the tendency to explore the neighborhood of prominent chemicals. This paints a picture of a “crowded frontier” [7], where multiple researchers focus their investigations on a very congested neighborhood of the discover- able space, rather than exploring the space of the unknown more broadly.
While these prominent chemicals may warrant more investigations, this example suggests that there could be more optimal ways to explore the map of knowledge. For example, the model estimates that, overall, the optimal strategy for uncovering 50 percent of the graph can be nearly 10 times more efficient than the random strategy, which tests all edges with equal probability. This illustrates that a deeper under- standing of how science evolves could help us accelerate the discipline’s growth, allowing us to strategically choose the best next experiments.
Notes:
1. Y. N. Harari, Sapiens: A Brief History of Humankind (London: Random House, 2014).
2. J. A. Evans, and J. G. Foster, Metaknowledge. Science, 331(6018), (2011),721–725.
3. R. D. King, J. Rowland, S. G. Olive et al., The automation of science. Science, 324(5923), (2009), 85–89.
4. J. Evans, and A. Rzhetsky, Machine science. Science, 329(5990), (2010),399–400.
5. D. R. Swanson, Migraine and magnesium: Eleven neglected connections. Perspectives in Biology and Medicine, 31(4), (1988), 526–557.
6. A. Rzhetsky, J. G. Foster, I. T. Foster, et al., Choosing experiments to accelerate collective discovery. Proceedings of the National Academy of Sciences, 112(47), (2015), 14569–14574.
7. P. Azoulay, J. Graff-Zivin, B. Uzzi, et al., Toward a more scientific science. Science, 361(6408), (2018), 1194–1197.
8. J. G. Foster, A. Rzhetsky, and J.A. Evans, Tradition and innovation in scientists’ research strategies. American Sociological Review, 80(5), (2015), 875–908.
Professor of Management and Organizations; Professor of Industrial Engineering and Management Sciences (courtesy); Director, Center for Science of Science and Innovation (CSSI); Co-Director, Ryan Institute on Complexity; Director, Northwestern Innovation Institute
About the Research
Excerpted from The Science of Science. Copyright (c) 2021 by Dashun Wang and Albert-László Barabási. Used with permission of the publisher, Cambridge University Press. All rights reserved.
Insight in your inbox
Receive our newsletters to keep up with the latest research and ideas from faculty at the Kellogg School of Management.
This website uses cookies and similar technologies to analyze and optimize site usage. By continuing to use our websites, you consent to this. For more information, please read our Privacy Statement.
Receive our newsletters to keep up with the latest research and ideas from faculty at the Kellogg School of Management.
This website uses cookies and similar technologies to analyze and optimize site usage. By continuing to use our websites, you consent to this. For more information, please read our Privacy Statement.